

Textscope®
Doc Parser
Textscope®
Doc Parser
Textscope® Doc Parser: Document Layout Analysis Solution
Textscope® Doc Parser is a powerful solution for analyzing document layouts, detecting paragraphs, images, tables, and other elements across diverse formats. It transforms both structural and non-textual information into actionable data, optimizing document usability and maximizing data value.
Key features of Doc Parser
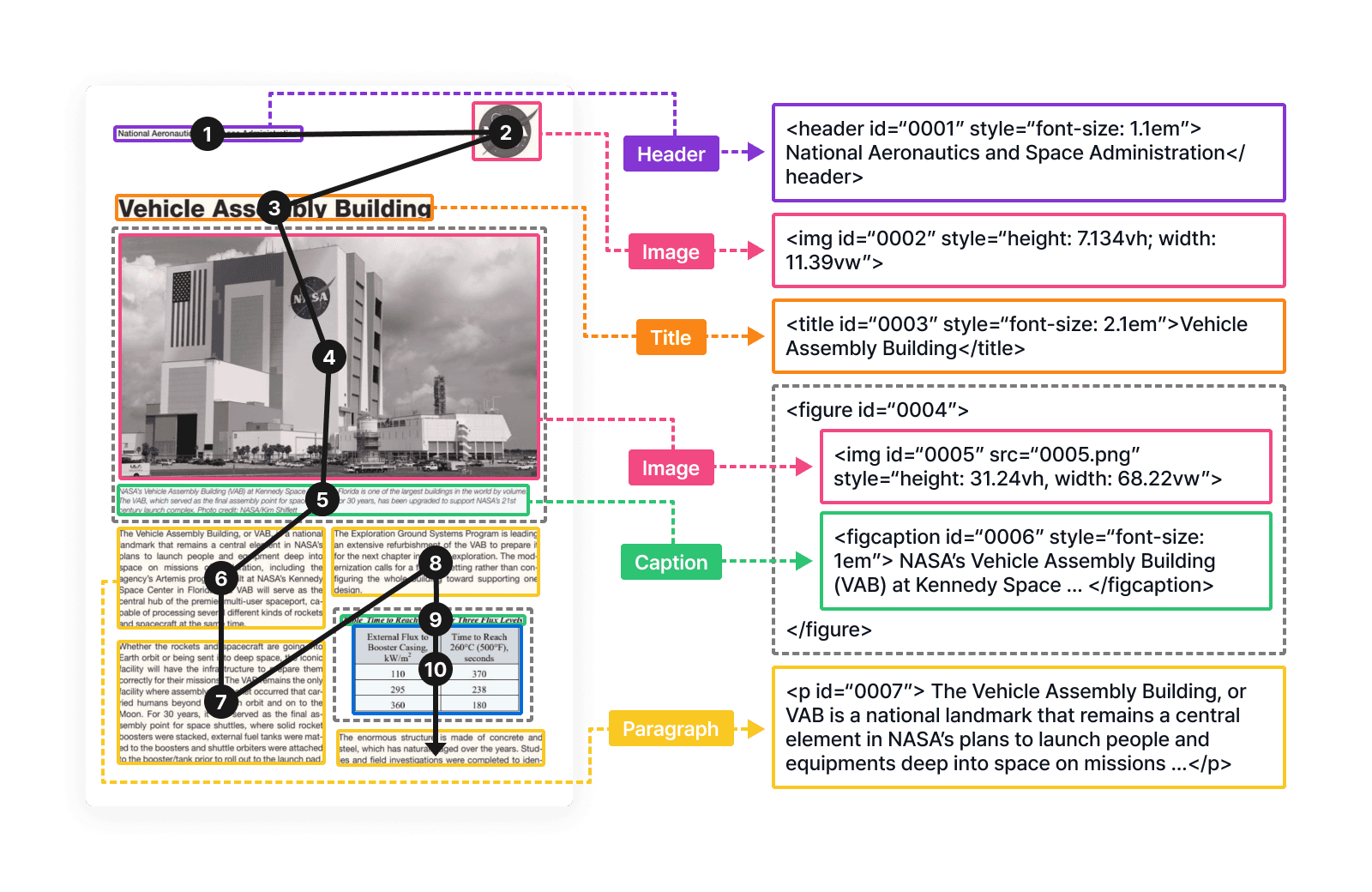
Analysis and extraction of document and table structures
Analysis and extraction of document and table structures
Recognition of over 10 different layout elements
Recognition of over 10 different layout elements
Document titles, section subtitles
Document titles, section subtitles
Text paragraphs, lists, equations
Text paragraphs, lists, equations
Tables, pictures, captions
Tables, pictures, captions
Header, footer, footnote
Header, footer, footnote
Arrangement of layout elements in a natural reading order
Arrangement of layout elements in a natural reading order
Detection of font sizes, image dimensions, and location
Detection of font sizes, image dimensions, and location
Relationships between figures/tables and their captions
Relationships between figures/tables and their captions
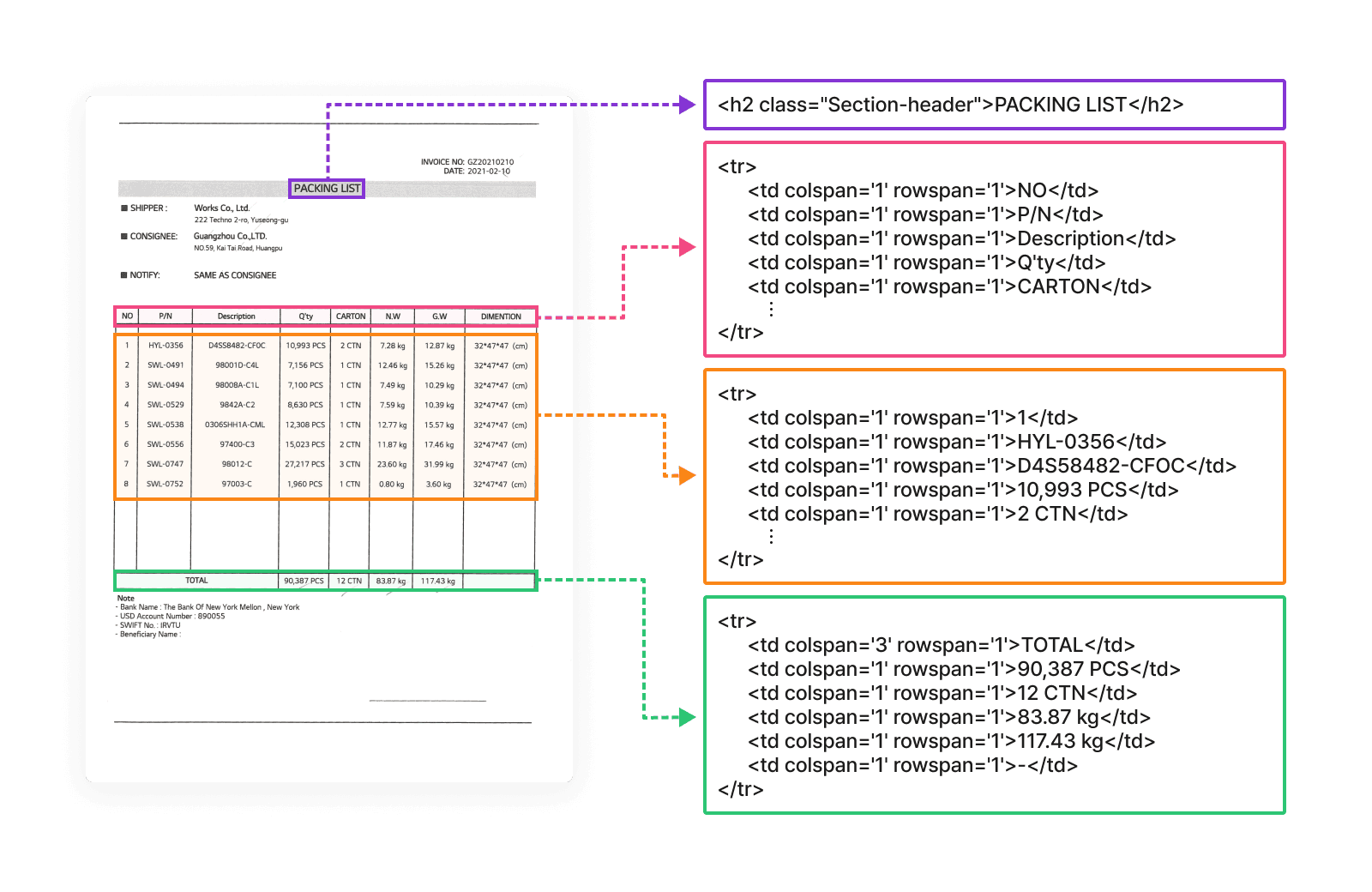
Table structure recognition
Table structure recognition
Table detection across various styles
Table detection across various styles
Identifies table layout elements using HTML tags like <table>, <thead>, <td>, and more
Identifies table layout elements using HTML tags like <table>, <thead>, <td>, and more
Table caption detection
Table caption detection
Supports recognition of merged cells
Supports recognition of merged cells
Header Information Recognition
Header Information Recognition
Other features of Doc Parser

Image file recognition
Recognize document elements such as layout, text, table, etc. in image files such as scan/fax documents
Works on low-quality images such as shadows, noise, and photographic angles
Exceptional accuracy in both printed and handwritten text recognition
AI-powered layout analysis for accurate image recognition
Image file recognition
Recognize document elements such as layout, text, table, etc. in image files such as scan/fax documents
Works on low-quality images such as shadows, noise, and photographic angles
Exceptional accuracy in both printed and handwritten text recognition
AI-powered layout analysis for accurate image recognition

Supports a variety of input/output file formats
Supports a variety of input/output file formats
Input
Input
Office documents: PDF, Hangul (hwp, hwpx), Word (doc, docx), PowerPoint (ppt, pptx), Excel (xls, xlsx)
Image documents: JPG, PNG, TIFF, BMP, GIF, PDF, etc
Office documents: PDF, Hangul (hwp, hwpx), Word (doc, docx), PowerPoint (ppt, pptx), Excel (xls, xlsx)
Image documents: JPG, PNG, TIFF, BMP, GIF, PDF, etc
Output
Output
Image documents: JPG, PNG, TIFF, BMP, GIF, PDF, etcText formats: export as html, markdown, text, and other text-based formats
Table exports: extract tables and export them as excel or csv files
Image exports: save extracted images as standalone files (jpg, png, etc.)
Image documents: JPG, PNG, TIFF, BMP, GIF, PDF, etcText formats: export as html, markdown, text, and other text-based formats
Table exports: extract tables and export them as excel or csv files
Image exports: save extracted images as standalone files (jpg, png, etc.)

LLM/RAG services and integration ready
Enhanced Information Delivery: Elevates RAG and LLM search and response accuracy with richer document data.
Data Integration for Vector Embedding: Streamlines data connections for vector embedding
Customized Data Formatting: Tailors data formats to boost LLM performance.
LLM/RAG services and integration ready
Enhanced Information Delivery: Elevates RAG and LLM search and response accuracy with richer document data.
Data Integration for Vector Embedding: Streamlines data connections for vector embedding
text03
LLM/RAG services and integration ready
Enhanced Information Delivery: Elevates RAG and LLM search and response accuracy with richer document data.
Data Integration for Vector Embedding: Streamlines data connections for vector embedding
Customized Data Formatting: Tailors data formats to boost LLM performance.
Doc Parser can be utilized as follows.

01
01
Choose a document
Choose a document
It supports office documents (PDF, Hangul, Word, PowerPoint, Excel, etc.) and image documents (JPG, PNG, TIFF, BMP, GIF, PDF, etc.).
It supports office documents (PDF, Hangul, Word, PowerPoint, Excel, etc.) and image documents (JPG, PNG, TIFF, BMP, GIF, PDF, etc.).
02
02
Document Parsing
Document Parsing
Recognizes objects in a document, such as text, pictures, and tables.
Recognizes objects in a document, such as text, pictures, and tables.
03
03
The result
The result
The recognition result is converted into structured data such as HTML, Markdown, and Text, and the extracted image can be stored as a separate file (jpg, png, etc.).
The recognition result is converted into structured data such as HTML, Markdown, and Text, and the extracted image can be stored as a separate file (jpg, png, etc.).
04
04
Application
Application
Interworks with RAG/LLM services through Vector Embedding. You can also parse the contents of a document and automatically convert it into a web page for mobile or PC (html) to provide the information contained in the document over the web.
Interworks with RAG/LLM services through Vector Embedding. You can also parse the contents of a document and automatically convert it into a web page for mobile or PC (html) to provide the information contained in the document over the web.

Interested in learning more about
Doc Parser?
Please contact us right away. A Document AI specialist will provide you
with the best ways to enhance the value of your document data
as quickly and comprehensively as possible.

Interested in learning more
about
Doc Parser?
Please contact us right away. A Document AI specialist will provide you with the best ways to enhance the value of your document data as quickly and comprehensively as possible.
7th Floor, JBI Building, 10 Bangbaechun-ro 2-gil, Seocho-gu, Seoul
Product & Technical Consulting
T. +82) 2 6289 0501
General Inquiry
T. +82) 2 6331 1853
7th Floor, JBI Building, 10 Bangbaechun-ro 2-gil, Seocho-gu, Seoul
Product & Technical Consulting
General Inquiry